
Im letzten Artikel habe ich mein MCP-Bild-Tool um Referenzbilder erweitert. Dabei fiel auf: je nach Modell sehen die Ergebnisse völlig unterschiedlich aus. Also habe ich sie systematisch gegeneinander antreten lassen.
Die Kandidaten
Alle Modelle hängen bei mir am selben MCP-Tool, ich schalte nur Provider und Modell um:
- Imagen 4 (Google,
imagen-4.0-generate-001): reines Text→Bild. Steuerung überaspect_ratio, liefert bei 16:9 ein 1408×768-Bild. - gpt-image-1 (OpenAI): Text→Bild und Bild-Edit (
images.edit), kann also Referenzbilder verarbeiten. Feste Ausgabegrößen, bei 16:9 ein 1536×1024-Bild. - gemini-2.5-flash-image (Google): das bild-fähige Gemini-Modell, nimmt ebenfalls Referenzbilder. Mein Tool schaltet automatisch darauf, sobald ein Referenzbild dabei ist und Provider
geminigewählt ist.
Der entscheidende Unterschied steckt schon hier: zwei der drei nehmen ein Bild als Input – Imagen nicht.
Test 1: Logo-Treue mit Referenzbild
Aufgabe: ein Tablet, das das Home-Assistant-Logo auf dem Display zeigt. Die beiden bild-fähigen Modelle (gpt-image-1 und gemini-2.5-flash-image) bekamen das echte Logo als Referenzbild mit – exakt dasselbe Bild. Imagen bekam nur eine Textbeschreibung, denn es kann gar kein Bild als Input nehmen.
Rangfolge eindeutig: gpt-image-1 > gemini-2.5-flash-image > Imagen. Beide bild-fähigen Modelle schlagen Imagen klar – logisch, denn das ist eine Architekturgrenze, kein Patzer: ohne Bild-Input muss Imagen das Logo aus Worten rekonstruieren und scheitert an Markenzeichen zuverlässig. gpt-image-1 trifft die Vorlage am genauesten; gemini-2.5-flash-image kommt nah ran, interpretiert das Logo aber freier. Sobald Marke, Logo oder ein konkretes Produkt exakt aussehen muss, führt an einem Referenzbild kein Weg vorbei.
Test 1b: Die Wortmarke – der eigentliche Lackmustest
Ein Icon ist das eine, Text das andere. Bildmodelle sind berüchtigt dafür, Schrift zu verstümmeln. Also der härtere Test: unser eigenes devmaker.net-Logo inklusive Wortmarke als Referenz – wieder bekamen die beiden bild-fähigen Modelle das echte Logo, Imagen nur die Beschreibung.



Genau hier zahlt sich das Referenzbild am stärksten aus. gpt-image-1 ist das einzige Modell, das Symbol und Schriftzug zusammen zuverlässig trifft. gemini-2.5-flash-image kommt nah ran, patzt aber typisch bei Text – ein fehlender Buchstabe reicht für ein kaputtes Logo. Und Imagen zeigt, warum „beschreib das Logo halt“ keine Lösung ist: die Buchstaben kann es abtippen, die Markenidentität nicht erfinden. Für alles mit Schrift – Wortmarken, Beschriftungen, UI-Texte – ist gpt-image-1 mit Referenz aktuell die einzige verlässliche Wahl.
Test 2: Helligkeit & Belichtung
Gleicher Prompt, bewusst ohne Helligkeitsangabe: „developer workspace at night, moody atmosphere". Das Ergebnis hat meine Erwartung umgedreht.

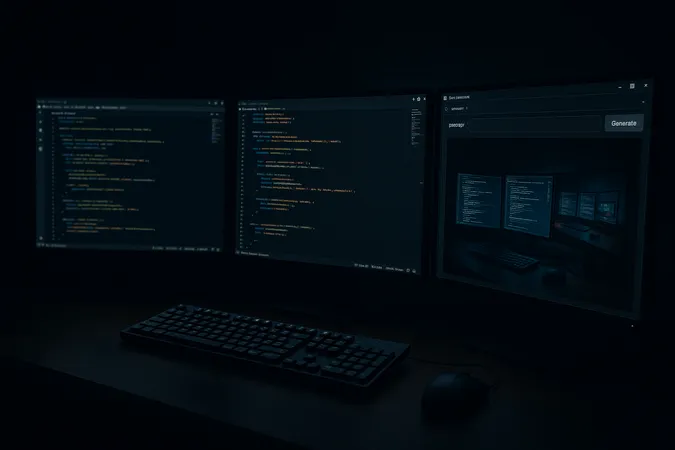
Lektion aus der Praxis: beide Modelle können zu dunkel geraten – aber gpt-image-1 interpretiert Stimmungs-Wörter deutlich aggressiver. Wer dunkle Hero-Bilder will (wie hier im Terminal-Theme), muss die Helligkeit trotzdem explizit ansagen: „well-lit subject, clearly visible, balanced exposure". Sonst sieht man am Ende nur noch das hellste Element im Bild.
Test 3: Abstraktes Konzept & Text-Artefakte
Für konzeptionelle Heroes (Agents, Pipelines, „X vs. Y") gibt es kein fotografierbares Motiv. Gleicher Prompt an beide: ein glühender „Agent-Loop"-Kern, ausdrücklich no text, no letters.


Hier liefern beide brauchbar ab und – wichtig – keines schmuggelt Text ein. Das „no text"-Pattern wirkt bei beiden, ist aber kein Garant: sobald im Motiv Schrift vorkommt (Buttons, Diagramm-Labels, Tastatur), produzieren beide gern mal verstümmelte Pseudo-Buchstaben – siehe der verschluckte Buchstabe oben bei der Wortmarke. Tendenz: Imagen geht Richtung knackiger Stock-Look, gpt-image-1 Richtung Illustration.
Output-Größen & ein Stolperstein
Imagen steuert das Format über aspect_ratio (16:9 → 1408×768), gpt-image-1 kennt nur feste Größen (16:9 → 1536×1024). gemini-2.5-flash-image hat meine 16:9-Angabe in beiden Referenz-Tests schlicht ignoriert – einmal quadratisch (1024×1024), einmal extrem breit (2048×512). Fies, wenn man feste Hero-Slots befüllt; fürs Cropping also unbedingt gegenprüfen.
Der Stolperstein, der mich eine fehlgeschlagene Generierung gekostet hat: Wenn man den Provider umstellt, aber das Modell vergisst, zieht der Resolver weiter das Default-Modell aus den Settings – und das ist ein Imagen-Modell:
# Falsch: Provider gesetzt, Modell vergessen
# -> der Resolver zieht das Imagen-Modell aus den Settings
generate_ai_image(prompt="...", provider="openai")
# 400: The model 'imagen-4.0-generate-001' does not exist
# Richtig: Provider UND Modell zusammen angeben
generate_ai_image(prompt="...", provider="openai", model="gpt-image-1")Wo das läuft
Kurz zur Einordnung, damit das Setup ehrlich bleibt: Die produktive Wagtail-Site liegt auf einem netcup-Server. Diese Experimente laufen aber in meiner Dev-Umgebung lokal auf einem kleinen Mini-PC im Homelab – dort hängt das MCP-Tool dran, das die Bildaufrufe absetzt. Die Bildmodelle selbst rechnen ohnehin in der Cloud, der Mini-PC orchestriert nur. Für genau so eine Always-on-Dev-Kiste nutze ich diesen hier:
Anzeige · Affiliate-Link – kaufst du darüber, erhalte ich ggf. eine Provision. Für dich ändert sich am Preis nichts.

Was ich weggelassen habe
- Exakte Kosten & Latenz: beides schwankt mit Last und Größe – ohne sauberes Messsetup wären Zahlen geraten. Gefühlt: gpt-image-1 etwas langsamer, Imagen 4 zügig.
- Midjourney / Stable Diffusion: bewusst draußen – mir ging es um die Modelle, die direkt an meinem Tool hängen.
- Andere Formate: getestet habe ich 16:9-Heroes (außer den gemini-Ausreißern). Bei Quadrat/Portrait kann das Bild anders ausfallen.
Fazit: Wann welches Modell
- Imagen 4 ist meine Default-Wahl für abstrakte, helle Heroes mit scharfer, sauberer Optik – schnell und unkompliziert, aber ohne Referenzbild.
- gpt-image-1 nehme ich, sobald ein Referenzbild ins Spiel kommt (Logo, Produkt, Marke) oder ein Maskottchen über mehrere Bilder konsistent bleiben soll. Beste Logo- und vor allem Text-/Wortmarken-Treue. Preis: explizit Helligkeit prompten, sonst wird's zu dunkel.
- gemini-2.5-flash-image ist die schnelle Referenzbild-Alternative aus dem Google-Lager – nah dran, aber freier in der Interpretation, verschluckt bei Schrift schon mal einen Buchstaben und hat ein Format-Eigenleben.
Logo/Marke muss exakt stimmen – erst recht mit Text/Wortmarke? → gpt-image-1 mit Referenzbild. Schnelle Referenzbild-Alternative ohne Schrift? → gemini-2.5-flash-image (Format gegenprüfen). Schneller, scharfer Konzept-Hero ohne Vorlage? → Imagen. In allen Fällen: Helligkeit explizit ins Prompt schreiben.
Anzeige · Affiliate-Link – kaufst du darüber, erhalte ich ggf. eine Provision. Für dich ändert sich am Preis nichts.


